During the Ironic sessions at the recent OpenStack Dublin PTG in Spring 2018, there were some discussions on adding a further burn in step to the OpenStack Bare Metal project (Ironic)
state machine. The notes summarising the sessions were reported to the
openstack-dev list. This blog covers the CERN burn in process for the systems delivered to the data centers as one example of how OpenStack Ironic users could benefit from a set of open source tools to burn in newly delivered servers as a stage within the Ironic workflow.
CERN hardware procurement follows a
formal process compliant with public procurements. Following a market survey to identify potential companies in CERN's member states, a tender specification is sent to the companies asking for offers based on technical requirements.
Server burn in goals
Following the public procurement processes at CERN, large hardware deliveries occur once or twice a year and smaller deliveries multiple times per year. The overall resource management at CERN was covered in a previous
blog. Part of the steps before production involves burn in of new servers. The goals are
- Ensure that the hardware delivered complies with CERN Technical Specifications
- Find systematic issues with all machines in a delivery such as bad firmware
- Identify failed components in single machines
- Provoke early failure in failing components due to high load during stress testing
Depending on the hardware configuration, the burn-in tests take on average around two weeks but do vary significantly (e.g. for systems with large memory amounts, the memory tests alone can take up to two weeks). This has been found to be a reasonable balance between achieving the goals above compared to delaying the production use of the machines with further testing which may not find more errors.
Successful execution of the CERN burn in processes is required in the tender documents prior to completion of the invoicing.
Workflow
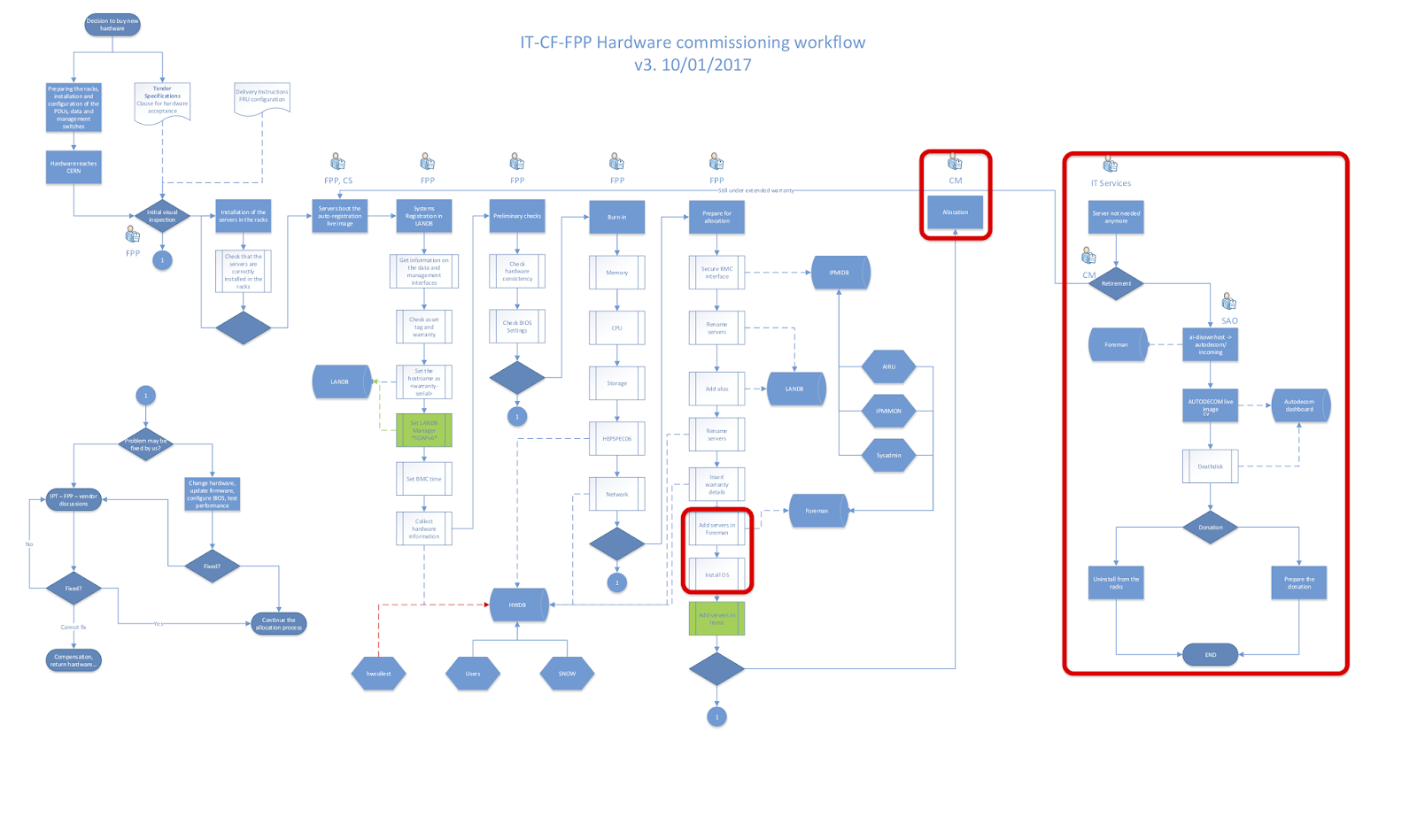
The CERN hardware follows a lifecycle from procurement to retirement as outlined below. The parts marked in red are the ones currently being implemented as part of the CERN Bare Metal deployment.
As part of the evaluation, test systems are requested from the vendor and these are used to validate compliance with the specifications. The results are also retained to ensure that the bulk equipment deliveries correspond to the initial test system configurations and performance.
Preliminary Checks
CERN requires that the Purchase Order ID and an unique System Serial Number are set in the NVRAM of the Baseboard Management Controller (BMC), in the Field Replaceable Unit (FRU) fields Product Asset Tag (PAT) and Product Serial (PS) respectively:
# ipmitool fru print 0 | tail -2
Product Serial : 245410-1
Product Asset Tag : CD5792984
The Product Asset Tag is set to the CERN delivery number and the Product Serial is set to the unique serial number for the system unit.
Likewise, certain BIOS fields have to be set correctly such as booting from network before disk to ensure the systems can be easily commissioned.
Once these basic checks have been done, the burn in process can start. A configuration file, containing the burn-in tests to be run, is created according on the information stored in the PAT and PS FRU fields. Based on the content of the configuration file, the enabled tests will automatically start.
Burn in
The burn in process itself is highlighted in red in the workflow above, consisting of the following steps
- Memory
- CPU
- Storage
- Benchmarking
- Network
Memory
The memtest stress tester is used for validation of the RAM in the system. Details of the tool are available at
http://www.memtest.org/.
CPU
Testing the CPU is performed using a set of burn tools, burnK7 or burnP6, and burn MMX. These tools not only test the CPU itself but are also useful to find cooling issues such as broken fans since the power load is significant with the processors running these tests.
Disk
Disk burn ins are intended to create the conditions for early drive failure. The
bathtub curve aims to cause the early failure drives to fail prior to production.
With this aim, we use the
badblocks code to repeatedly read/write the disks. SMART counters are then checked to see if there are significant numbers of relocated bad blocks and the CERN tenders require disk replacement if the error rate is high.
We still use this process although the primary disk storage for the operating system has now changed to SSD. There may be a case for minimising the writing on an SSD to maximise the life cycle of the units.
Benchmarking
Many of the CERN hardware procurements are based on price for total compute capacity needed. With the nature of most of the physics processing, the total throughput of the compute farm is more important than the individual processor performance. Thus, it may be that the most total performance can be achieved by choosing processors which are slightly slower but less expensive.
CERN currently measures the CPU performance using a set of benchmarks based on a subset of the SPEC 2006 suite. The subset, called HEPSpec06, is run in parallel on each of the cores in the server to determine the total throughput from the system. Details are available at the
HEPiX Benchmarking Working Group web site.
Since the offers include the expected benchmark performance, the results of the benchmarking process are used to validate the technical questionnaire submitted by the vendors. All machines in the same delivery would be expected to produce similar results so variations between different machines in the same batch are investigated.
CPU benchmarking can also be used to find problems where there is significant difference across a batch, such as incorrect BIOS settings on a particular system.
Disk performance is checked using a reference
fio access suite. A minimum performance level in I/O is also required in the tender documents.
Networking
Networking interfaces are difficult to burn in compared to disks or CPU. To do a reasonable validation, at lest two machines are needed. With batches of 100s of servers, a simple test against a single end point will produce unpredictable results.
Using a network broadcast, the test finds other machines running the stress test, they pair up and run a number of tests.
- iperf3 is used for bandwidth, reversed bandwidth, udp and reversed udp
- iperf for full duplex testing (currently missing from iperf3)
- ping is used for congestion testing
Looking forward
CERN is currently deploying Ironic into production for bare metal management of machines. Integrating the burn in and retirement stages into the bare metal management states would bring easy visibility of the current state as the deliveries are processed.
The retirement stage is also of interest to ensure that there is no CERN configuration in the servers (such as Ironic BMC credentials or IP addresses). CERN has often donated retired servers to other high energy physics sites such as
SESAME in Jordan and
Morocco which requires a full server factory reset before dismounting. This retirement step would be a more extreme cleaning followed by complete removal from the cloud.
Acknowledgements
- CERN IT department - http://cern.ch/it
- CERN Ironic and Rework Contributors
- Alexandru Grigore
- Daniel Abad
- Mateusz Kowalski
References