
For several OpenStack releases, the Identity service in OpenStack offers an additional token format
than UUID, called Fernet. This token format
has a series of advantages over the UUID, the most prominent for us is that it
doesn't need to be persisted. We were also interested in a speedup of the token creation and validation.
At CERN, we have
been using the UUID format for the tokens since the beginning of the cloud
deployment in 2013. Normally in the keystone database we have around
300,000 tokens with an expiration of 1 day. In order to keep the database size
controlled, we run the token_flush procedure every hour.
In the Mitaka
release, all remaining bugs were sorted out and since the Ocata release of
OpenStack, Fernet is now the default. Right now, we are
running keystone in Mitaka and we decided to migrate to the Fernet token format
before the upgrade of the Ocata release.
Before reviewing the upgrade from UUID to Fernet, let's have a brief look on the architecture of the identity
service. The service resolves into a set of load balancers and then they
redirect to a set of backends running keystone under apache. This allows us to
replace/increase the backends transparently.
The very first
question is how many keys we would need. If we take the formula from [1]:
fernet_keys =
validity / rotation_time + 2
If we have a
validity of 24 hours and a rotation every 6 hours, we would need 24/6 + 2 = 6 keys
As we have
several backends, the first task is to distribute the keys among the backends,
for that we are using puppet that provides the secrets in the /etc/keystone/fernet-keys
folder. With that we ensure that a new introduced backend will always have the
last set of keys available.
The second task
is how to rotate them. In our case we are using a cronjob in our rundeck
installation that rotates the secrets and introduces a new one. This job is doing
exactly the same as the keystone-manage token-flush command. One important
aspect is that on each rotation, you need to reload or restart the Apache daemon
to load the keys from the disk.
So we prepare all
this changes in the production setup quite some time ago, and we were testing
that the keys were correctly updated and distributed. On April 5th, we
decided to go on. This is the picture of the API messages during the
intervention.

There
are two distinct steps in the API messages usage. The first one is a peak of invalid tokens. This is triggered by
the end users trying to validate UUID tokens after the change. The second peak
is related to OpenStack services that are using trusts, like Magnum and Heat.
From our past experience, these services can be affected by a massive invalidation of
tokens. The trust credentials are cached and you need to restart both
services so both services will get their Fernet tokens.
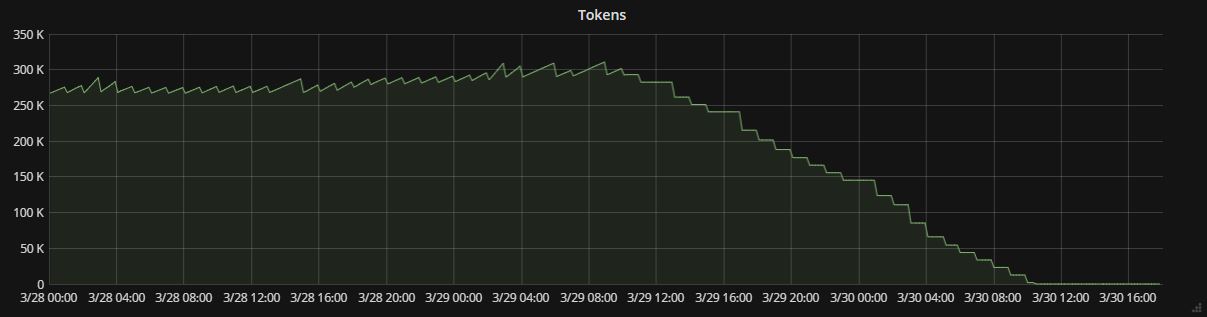
Below is a picture
of the size of the token table in the keystone database, as we are now in Fernet is going slowly down to zero, due to the hourly token_flush command I mentioned
earlier.
The last picture
is the response time of the identity service during the change. As you can see
the response time is better than on UUID as stated in [2]

In the Ocata
release, more improvements are on the way to improve the response time, and we
are working to update the identity service in the near future.
References:
- Fernet token FAQ at https://docs.openstack.org/admin-guide/identity-fernet-token-faq.html
- Fernet token performance at http://blog.dolphm.com/openstack-keystone-fernet-tokens/
- Payloads for Fernet token format at http://blog.dolphm.com/inside-openstack-keystone-fernet-token-payloads/
- Deep dive into Fernet at https://developer.ibm.com/opentech/2015/11/11/deep-dive-keystone-fernet-tokens/
Thank you sharing this Information
ReplyDeleteI also found Various useful links related to Devops, Docker & Kubernetes
Kubernetes Kubectl Commands CheatSheet
Introduction to Kubernetes Networking
Basic Concept of Kubernetes
Kubernetes Interview Question and Answers
Kubernetes Sheetsheat
Docker Basic Tutorial
Linux Sar Command Tutorial
Linux Interview Questions and Answers
Docker Interview Question and Answers
OpenStack Interview Questions and Answers
I had to read this three times because I wanted to be sure on some of your points. I agree on almost everything here, and I am impressed with how well you wrote this article.
ReplyDeleteDenial management software
Denials management software
Hospital denial management software
Self Pay Medicaid Insurance Discovery
Uninsured Medicaid Insurance Discovery
Medical billing Denial Management Software
Self Pay to Medicaid
Charity Care Software
Patient Payment Estimator
Underpayment Analyzer
Claim Status
Excellent post and very informative as well. Your knowledge appears very well on this topic and the way you have explained it, any new person can understand it easily. I would like you to keep writing like this and share your information with us. cheap comforter sets under 20 , cotton bed sheets online wholesale ,
ReplyDeleteOpenstack In Production - Archives: Migrating To Keystone Fernet Tokens >>>>> Download Now
ReplyDelete>>>>> Download Full
Openstack In Production - Archives: Migrating To Keystone Fernet Tokens >>>>> Download LINK
>>>>> Download Now
Openstack In Production - Archives: Migrating To Keystone Fernet Tokens >>>>> Download Full
>>>>> Download LINK Wh
Openstack In Production - Archives: Migrating To Keystone Fernet Tokens >>>>> Download Now
ReplyDelete>>>>> Download Full
Openstack In Production - Archives: Migrating To Keystone Fernet Tokens >>>>> Download LINK
>>>>> Download Now
Openstack In Production - Archives: Migrating To Keystone Fernet Tokens >>>>> Download Full
>>>>> Download LINK Yt